EDVR: Video Restoration with Enhanced Deformable
Convolutional Networks
2 Nanyang Technological University, Singapore
3 SIAT-SenseTime Joint Lab, Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences
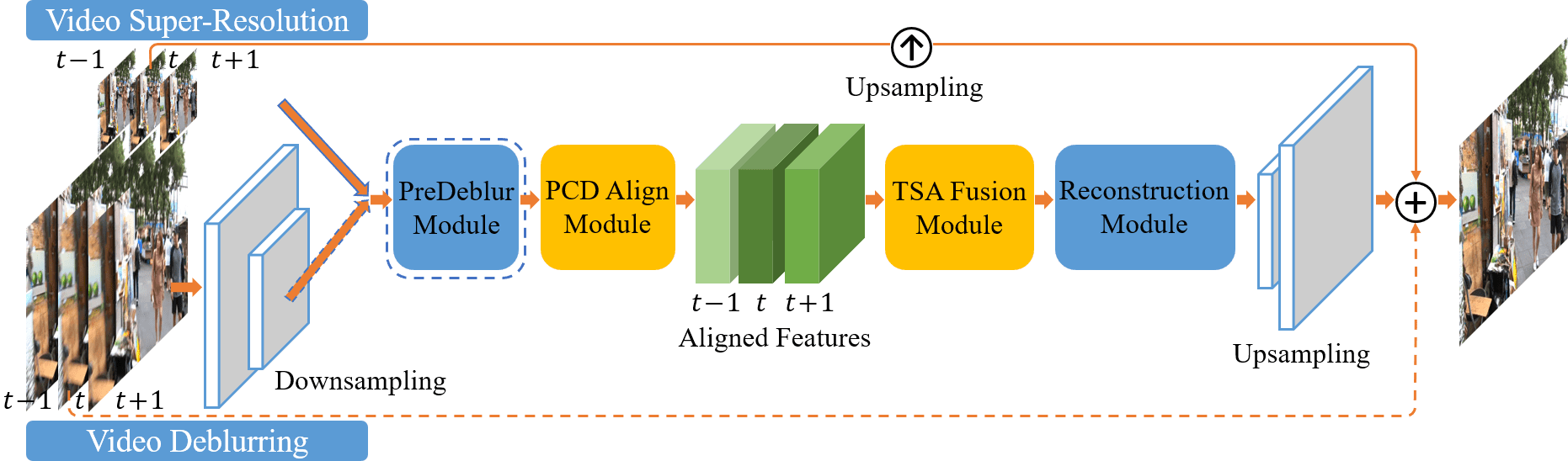
The EDVR framework. It is a unified framework suitable for various video restoration tasks, e.g., super-resolution and deblurring. Inputs with high spatial resolution are first down-sampled to reduce computational cost. Given blurry inputs, a PreDeblur Module is inserted before the PCD Align Module to improve alignment accuracy. We use three input frames as an illustrative example.
Highlights
- EDVR wins all four tracks in the NTIRE19 video restoration and enhancement challenges.
- We propose the PCD alignment module and TSA fusion module for effective alignment and fusion, respectively.

Abstract
Video restoration tasks, including super-resolution, deblurring, etc, are drawing increasing attention in the computer vision community. A challenging benchmark named REDS is released in the NTIRE19 Challenge. This new benchmark challenges existing methods from two aspects: (1) how to align multiple frames given large motions, and (2) how to effectively fuse different frames with diverse motion and blur. In this work, we propose a novel Video Restoration framework with Enhanced Deformable networks, termed EDVR, to address these challenges. First, to handle large motions, we devise a Pyramid, Cascading and Deformable (PCD) alignment module, in which frame alignment is done at the feature level using deformable convolutions in a coarse-to-fine manner. Second, we propose a Temporal and Spatial Attention (TSA) fusion module, in which attention is applied both temporally and spatially, so as to emphasize important features for subsequent restoration. Thanks to these modules, our EDVR wins the champions and outperforms the second place by a large margin in all four tracks in the NTIRE19 video restoration and enhancement challenges. EDVR also demonstrates superior performance to state-of-the-art published methods on video super-resolution and deblurring.
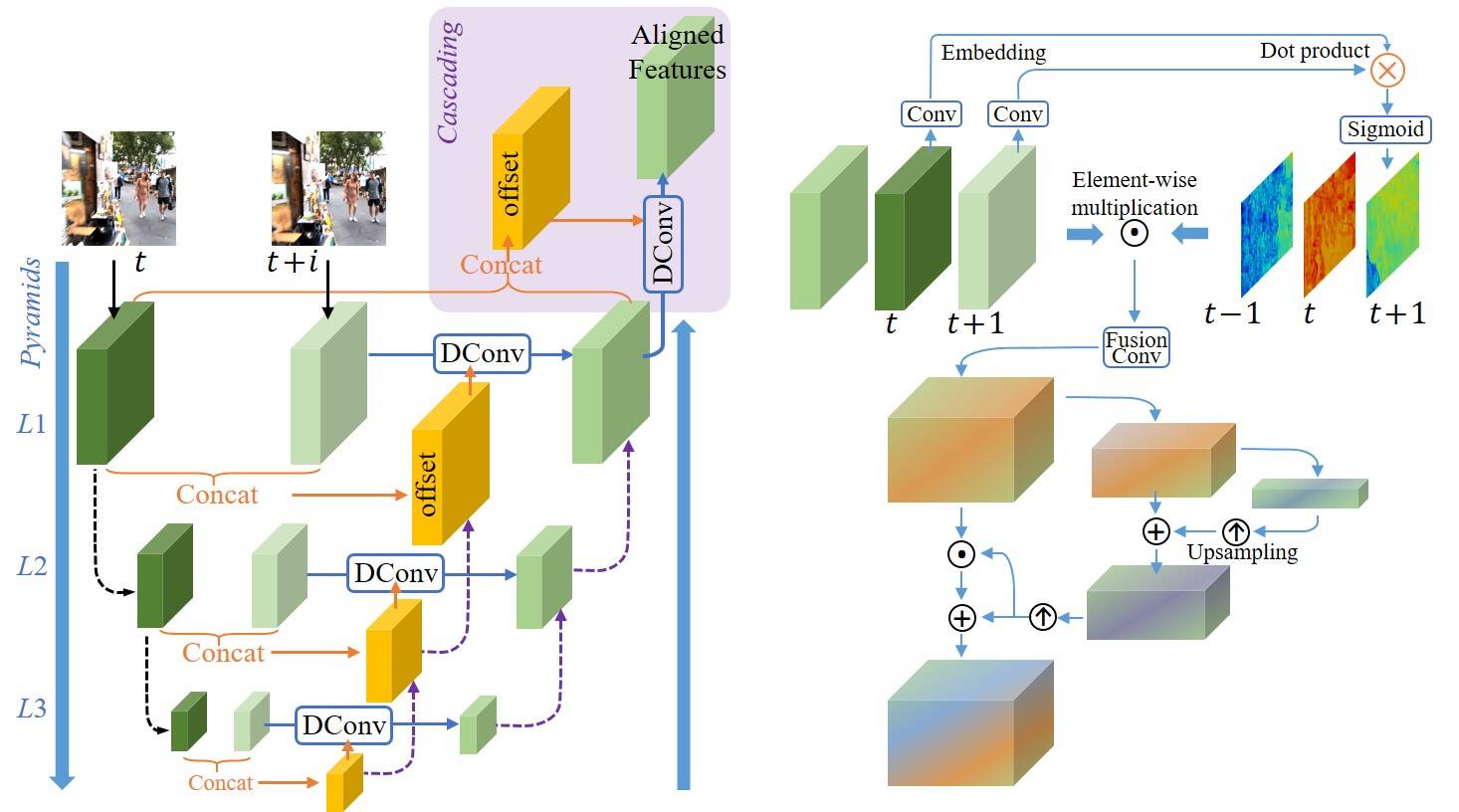
PCD and TSA Modules
Left: PCD alignment module with Pyramid, Cascading and Deformable convolution; Right: TSA fusion module with Temporal and Spatial Attention. See our paper for more details.
Ablation Studies on PCD and TSA Modules
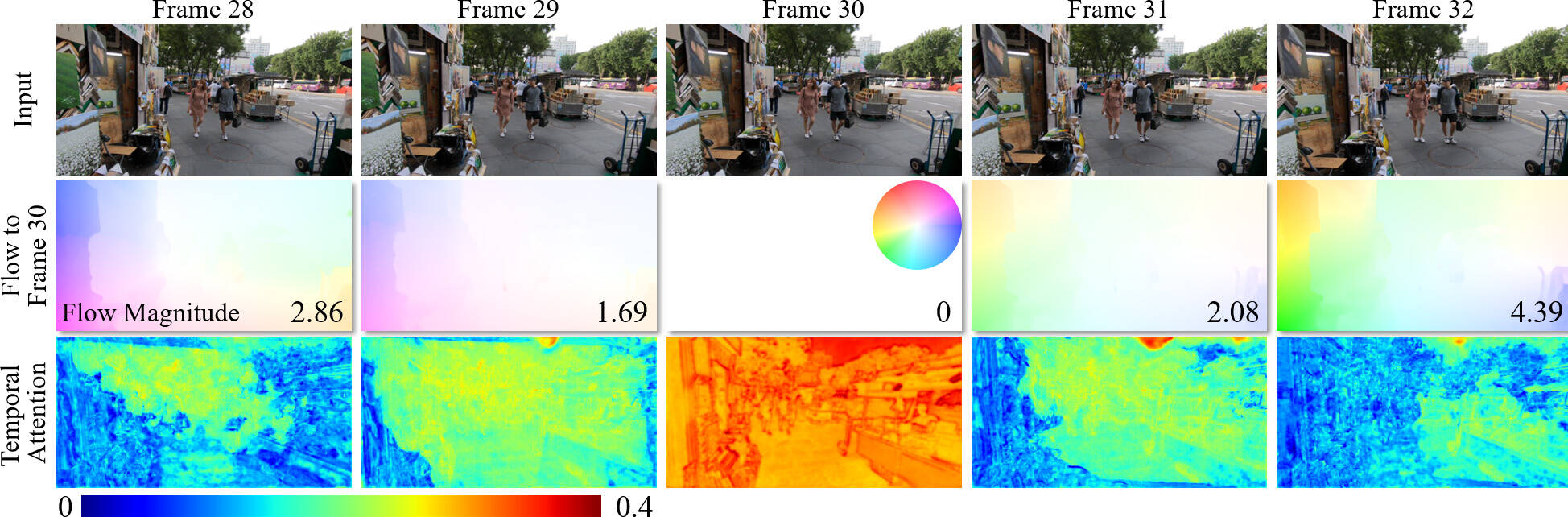
We show representative features before and after different alignment modules, and depict the flow (derived by PWCNet) between reference and neighboring features. Compared with the flow without PCD alignment, the flow of the PCD outputs is much smaller and cleaner, indicating that the PCD module can successfully handle large and complex motions.

We present the flow between the reference and neighboring frames, together with the temporal attention of each frame. It is observed that the frames and regions with lower flow magnitude tend to have higher attention, indicating that the smaller the motion is, the more informative the corresponding frames and regions are.
Results
1. Video Super-Resolution on Vid4 Dataset

2. Video Super-Resolution on Vimeo90K Dataset

3. Video Deblurring on REDS4 Dataset

4. Competition Results on REDS4 Dataset

Citation
@InProceedings{wang2019edvr,
author = {Wang, Xintao and Chan, Kelvin C.K. and Yu, Ke and Dong, Chao and Loy, Chen Change},
title = {EDVR: Video Restoration with Enhanced Deformable Convolutional Networks},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops},
month = {June},
year = {2019}
}
@Article{tian2018tdan,
author = {Tian, Yapeng and Zhang, Yulun and Fu, Yun and Xu, Chenliang},
title = {TDAN: Temporally deformable alignment network for video super-resolution},
journal = {arXiv preprint arXiv:1812.02898},
year = {2018}
}
Contact
If you have any question, please contact Xintao Wang at xintao.alpha@gmail.com.