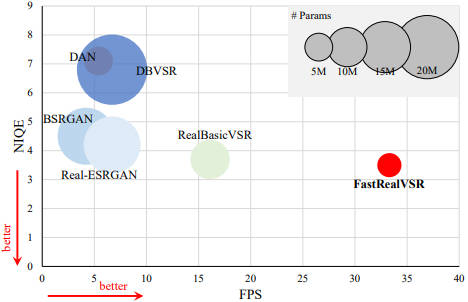
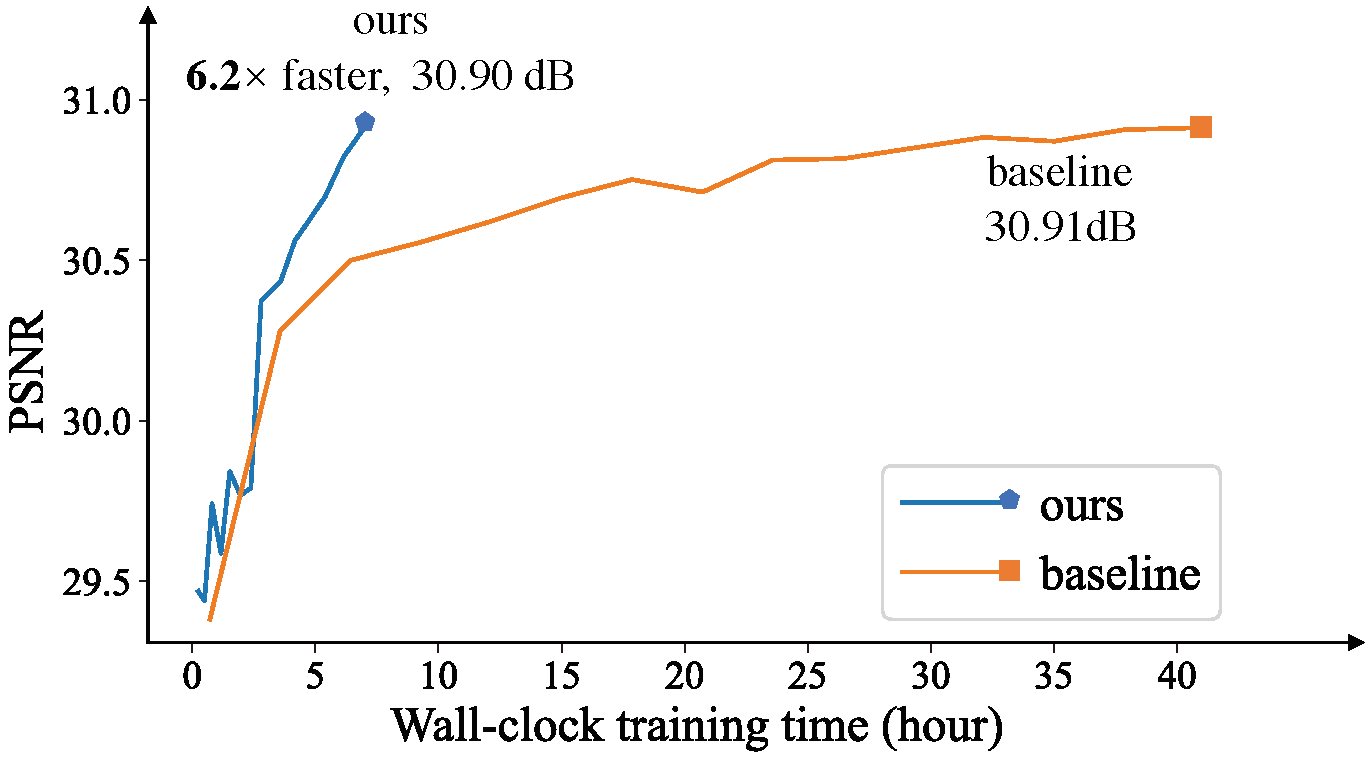
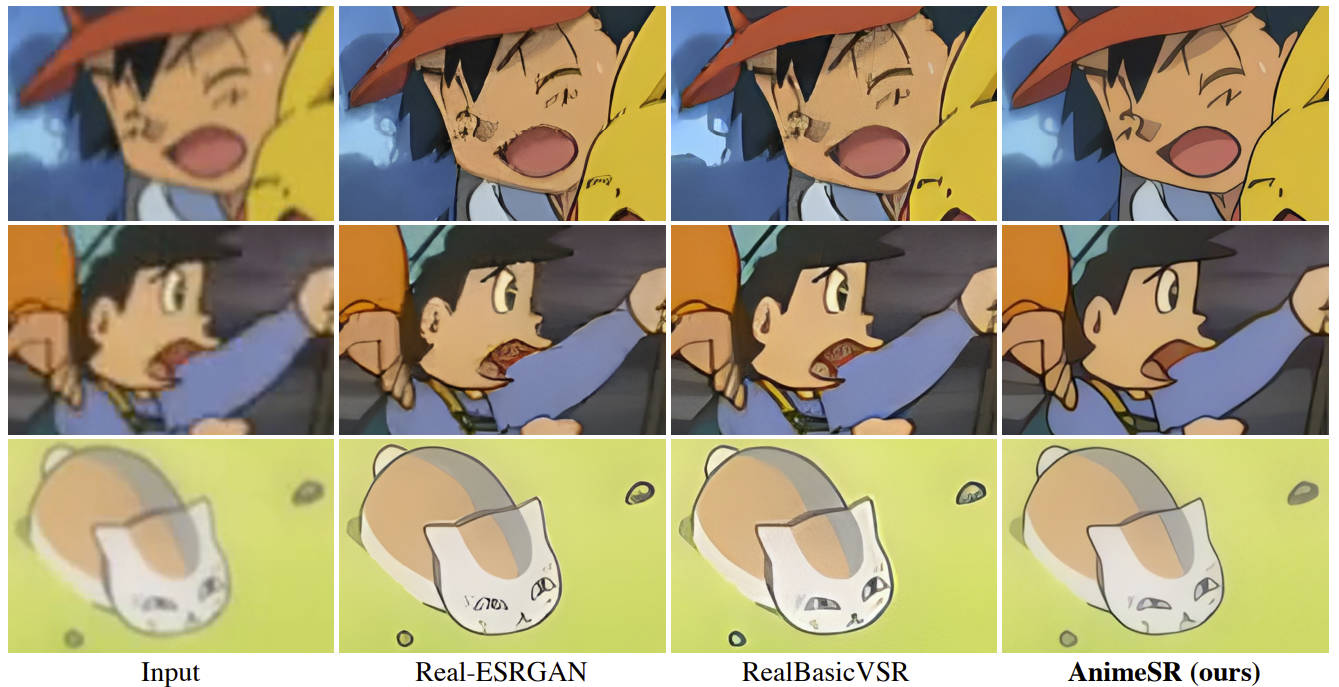
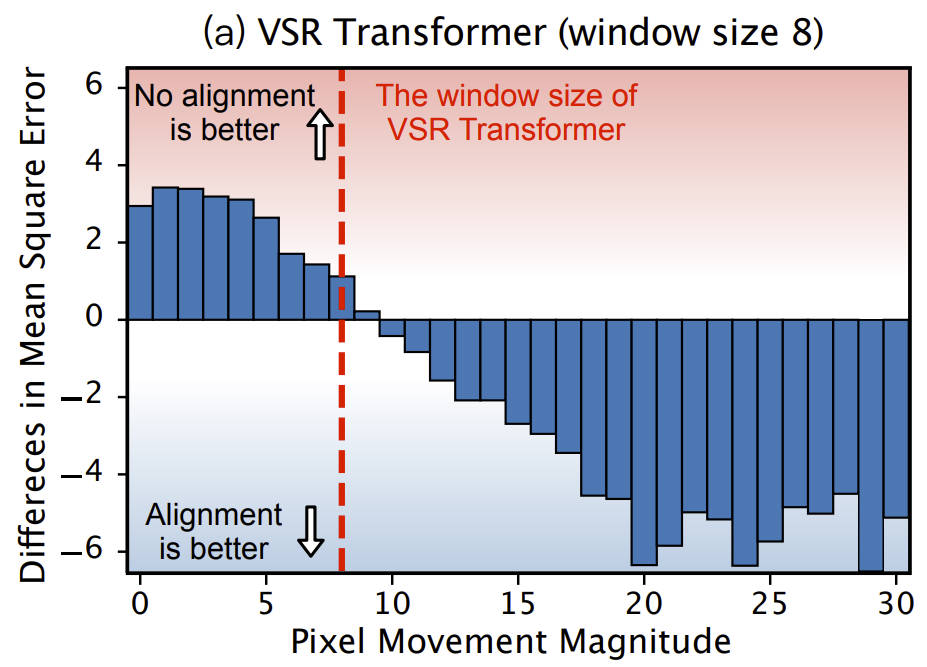
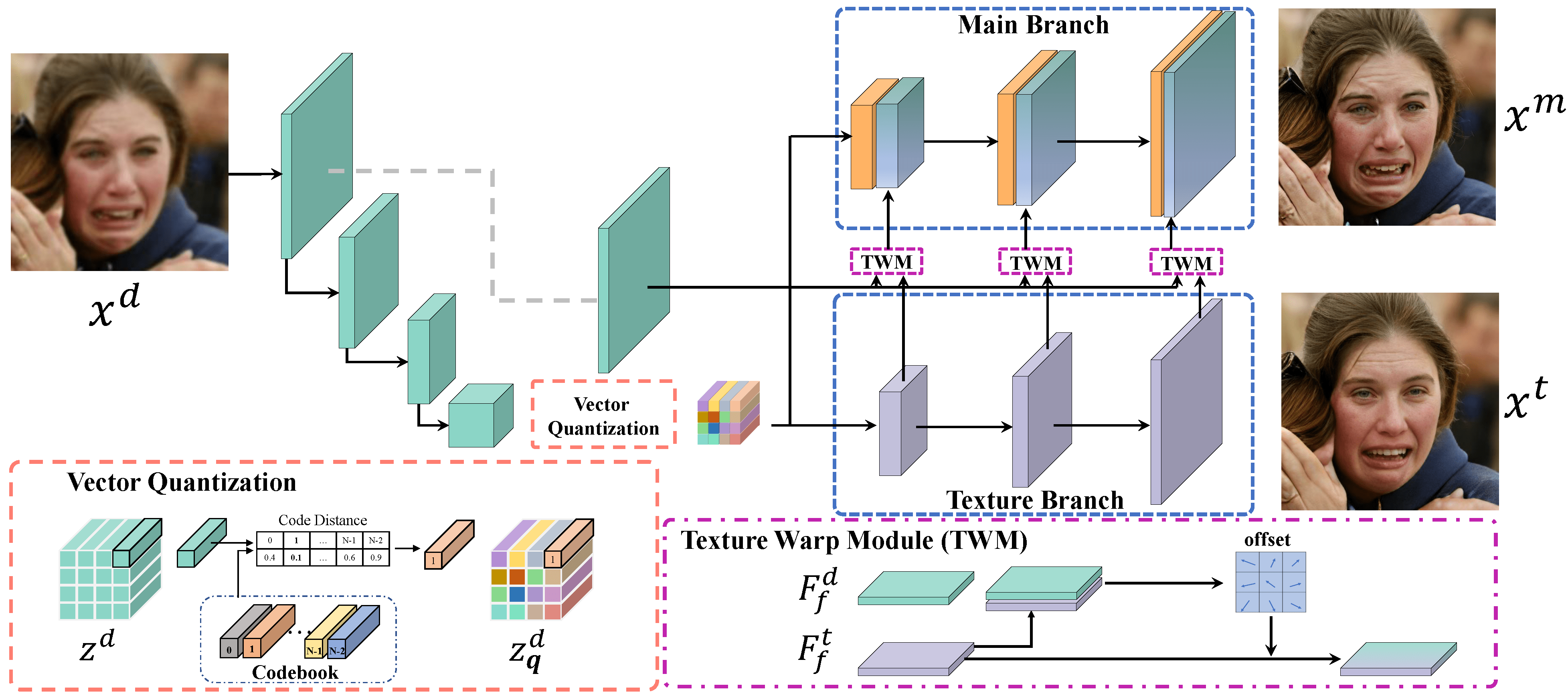
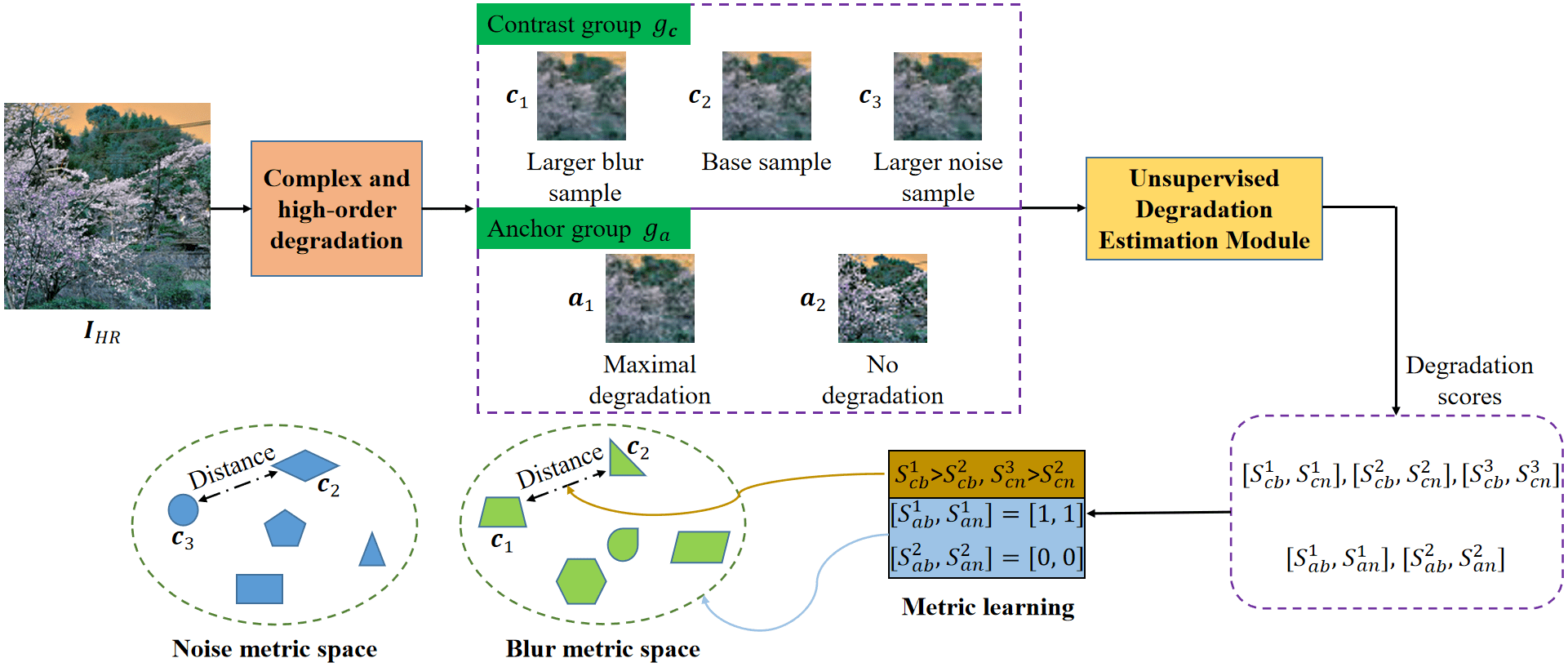
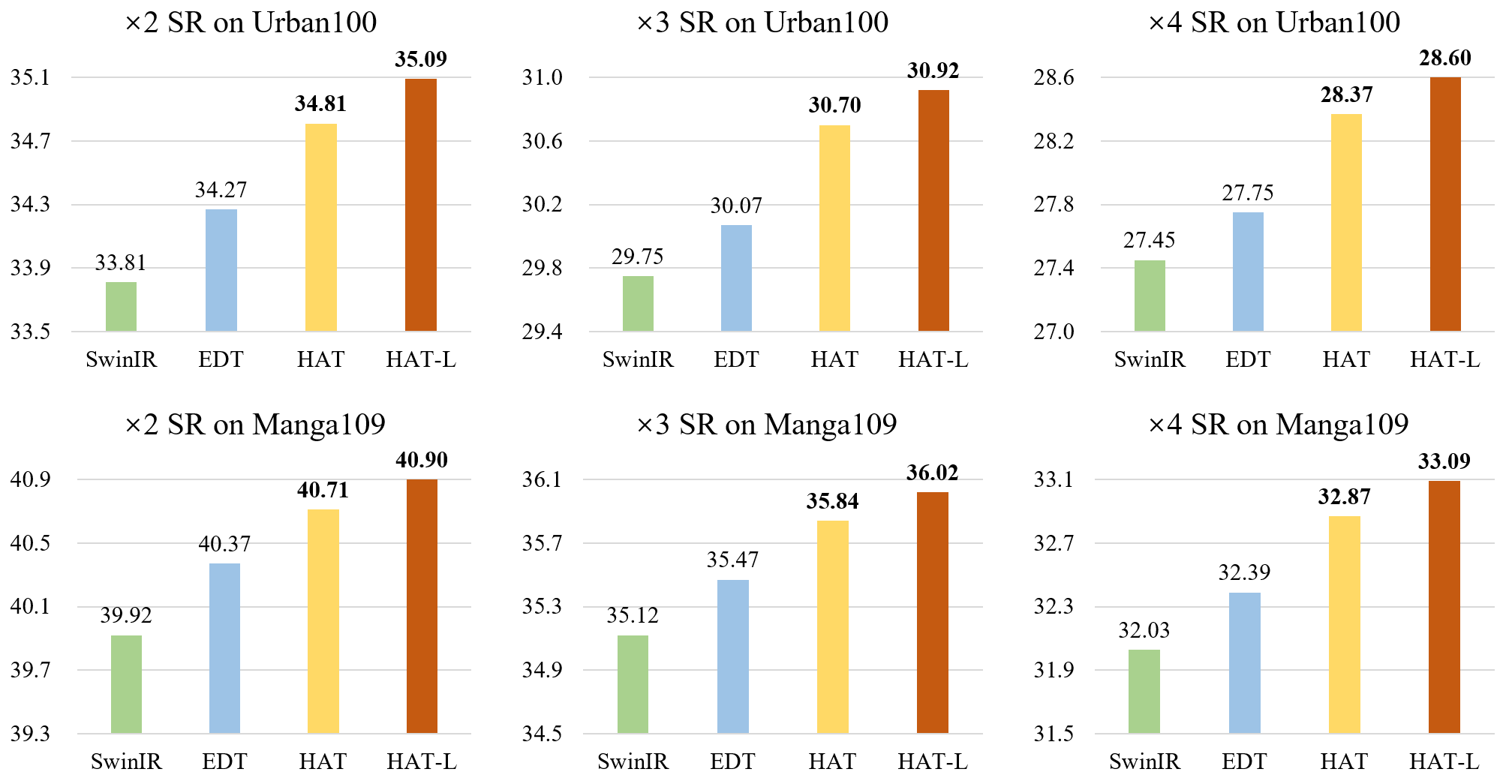We are actively looking for research interns and full-time researchers to work on related research topics, including but not limited to image and video generation/editing. Please feel free to drop me an email to xintao.wang@outlook.com if you are interested.
Previously, I was a senior staff researcher atTencent ARC Lab and Tencent AI Lab, where I led an effort on visual content generation (AIGC).
I got my Ph.D. degree from Multimedia
Lab (MMLab),
the Chinese University of Hong Kong, advised by Prof. Chen Change Loy and Prof. Xiaoou Tang.
I also work closely with Prof. Chao Dong.
Earlier, I obtained my bachelor's degree from Zhejiang University.